In diesem Kapitel lernen wir, wie in aktuellen Frameworks wie Keras und PyTorch das Lernen der Parameter funktioniert. Dazu werden Berechnungsgraphen definiert, in denen Gradienten lokal an den Knoten berechnet werden. Wir lernen die Grundprinzipien kennen, bestehend aus Vorwärts- und Rückwärtsverarbeitung, sehen uns die Anwendung in PyTorch sowie Keras an, und stellen den Zusammenhang zu Feedforwardnetzen her.
Konzepte in diesem Kapitel
Berechnungsgraph, lokale Ableitungsformel, Gradientenwert, Gradientenfluss, Autodiff, Autograd
Lernziele, um Ihren Lernfortschritt zu prüfen
Nach Abschluss dieses Kapitels können Sie
den Begriff des Berechnungsgraphen erläutern und dessen Rolle im Kontext der automatischen Differenzierung beschreiben
erklären, wie lokale Ableitungen bei Addition und Multiplikation an den Knoten eines Berechnungsgraphen berechnet und entlang des Graphen rückwärts propagiert werden
einfache Berechnungsgraphen analysieren und die Ableitungen einzelner Knotenwerte manuell berechnen
eine gegebene Formel in einen Berechnungsgraphen überführen
automatische Differenzierung mit PyTorch (autograd) und Keras (autodiff) praktisch anwenden, um Gradienten zu bestimmen
die Ergebnisse der automatischen Differenzierung mit klassischen Backpropagation-Formeln vergleichen und deren Zusammenhang erkennen
den praktischen Nutzen automatischer Differenzierung für das Training neuronaler Netze reflektieren
Updates dieser Seite
16.05.2025: Erklärungen in 7.3 etwas angepasst
28.04.2025: Neues Abstract, Ergänzungen bei 8.2
01.04.2025: Neu angelegt
Backpropagation ist sehr speziell auf die Struktur eines Neuronalen Netzes und seinen Schichten mit Gewichtsmatrizen zugeschnitten. In aktuellen Frameworks für neuronale Netze wird das Lernen per Gradientenabstieg allgemeiner gefasst. Die Berechnungen in einem Feedforward-Netz werden zunächst als Berechnungsgraph (computational graph) dargestellt. In diesem Berechnungsgraphen können dann Gradienten für jeden Knoten im Graphen bei jeder Rechnung automatisch berechnet werden, das nennt man auch automatische Differenzierung und wird bei Keras und PyTorch als “Motor” für Backpropagation benutzt. Bei PyTorch heißt dieses Feature Autograd, bei Keras automatic differentiation (Autodiff).
Diese im Berechnungsgraphen ermittelten Gradienten entsprechen den partiellen Ableitungen, die wir im Kapitel über Feedforward-Netze besprochen haben. Auch bei Automatic Differentiation gibt es immer eine Vorwärtsberechnung und eine Rückwärtsberechnung.
Ein allgemeines Verständnis von Gradienten und Backpropagation, das nicht direkt an Feedforward-Netze gekoppelt ist, wird ganz konkret relevant bei Techniken wie
Überall dort werden an vielen Stellen Parameter eingeführt, die durch Training “gelernt” werden und man fragt sich an diesen Stellen vielleicht, wie denn genau das umgesetzt wird.
Automatische Differenzierung kann als Verallgemeinerung von Backpropagation verstanden werden und ist ein mächtiges Konstrukt in der Welt des maschinellen Lernens.
Tipp: Andrej Karpathy erklärt automatisches Differenzieren einfach und mit Code
Andrej Karpathy erklärt in seinem Video zu Backpropagation (s. unten) das Konzept von Automatic Differentiation mit verblüffend einfachen Mitteln, indem er den Berechnungsgraphen und die Gradientenberechnung in wenigen Zeilen Code programmiert. Bei diesem Erklärungsansatz versteht man sehr intuitiv, dass man für beliebige Rechenoperationen die entsprechenden Paramter über Backpropagation “trainieren” kann.
Insofern kann ich Ihnen das Video nur sehr ans Herz legen. Der Code zu Karpathy’s Video liegt bei GitHub unter karpathy/micrograd (MIT-Lizenz).
Zur Person: Andrej Karpathy ist Informatiker und Spezialist für KI und Computer Vision. Er hat 2016 an der Stanford Universität bei Fei-Fei Li promoviert. 2017-2022 hat er die KI-Abteilung von Tesla aufgebaut, weltweit eine der führenden KI-Abteilungen, die die Autopilot-Mechanismen entwickelt. Er arbeitet seit 2023 wieder bei OpenAI, wo er bereits 2015-17 Research Scientist war. Alle Erklär-Videos seines YouTube-Kanals sind sehr sehenswert.
Ein gute Gelegenheit, Karpathy kennenzulernen, ist auch das Interview von Lex Fridman aus dem Jahr 2022 (etwas 3,5 Stunden, auch als Podcast verfügbar):
7.1 Berechnungsgraph
Wir können alle Funktionen und ihre Formeln, also insbesondere die Formeln zur Berechnung des Outputs \(\hat{y}\) eines Neuronalen Netzes, als Berechnungsgraph verstehen. So ein Graph besteht aus ganz einfachen Operationen wie Addition, Subtraktion, Multiplikation, Potenzieren, Sinus/Cosinus etc. und kann so komplexe Berechnungsformeln strukturiert abbilden.
In einem Neuronalen Netz ist die Berechnung der Verlustfunktion \(J\) auch eine große Berechnungsformel und kann somit mit einem Berechnungsgraphen dargestellt werden (das sollte auch aus den Abbildungen 8.1 und 8.2 hervorgehen).
Um zu verstehen, was mit einem Berechnungsgraphen gemeint ist, sehen wir uns ein einfaches Beispiel (das Sie auch im Video von Andrej Karpathy sehen können) an.
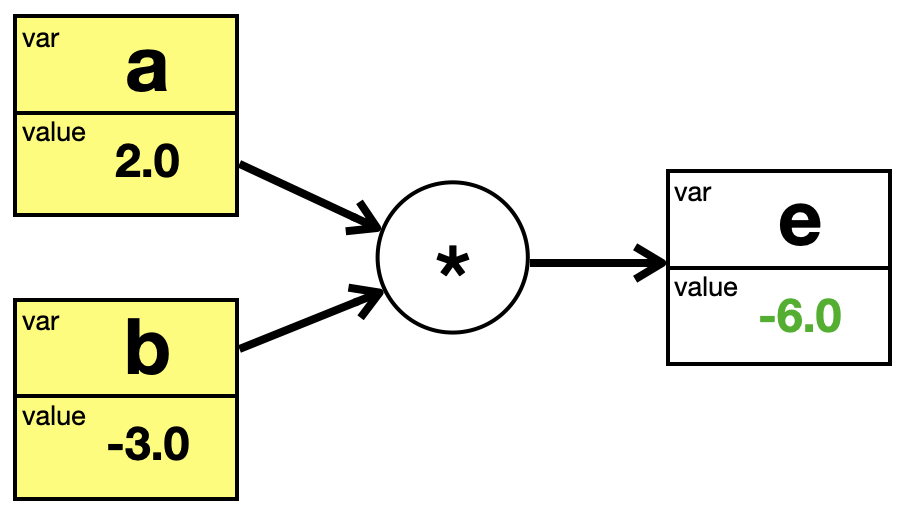
Nehmen wir folgende Gleichung, in der drei Variablen vorkommen:
\[
e = a \cdot b
\]
Und jetzt nehmen wir an, dass die Variablen \(a\) und \(b\) festgelegte Werte haben.
\[
\begin{align*}
a &:= 2 \\[2mm]
b &:= -3
\end{align*}
\]
Die Formel kann man in einen Berechnungsgraphen überführen, der die Variablen, ihre Werte und die Rechenoperation darstellt.
Wir könnten den Graphen benutzen, um den Wert von \(e\) zu berechnen (grüne Zahl). Wir gehen dazu von links nach rechts. Das nennt man auch Forward Pass (pass im Sinne von Durchgang):
Wir unterscheiden in unserem Graphen also bislang:
Variablen, die festgelegte Werte haben (Box gelb unterlegt); in der Welt der Graphen sind diese Boxen sogenannte Blätter (engl. leaf), wohingegen die anderen Boxen Zwischenknoten sind
Werte, die berechnet werden müssen (grüne Zahl)
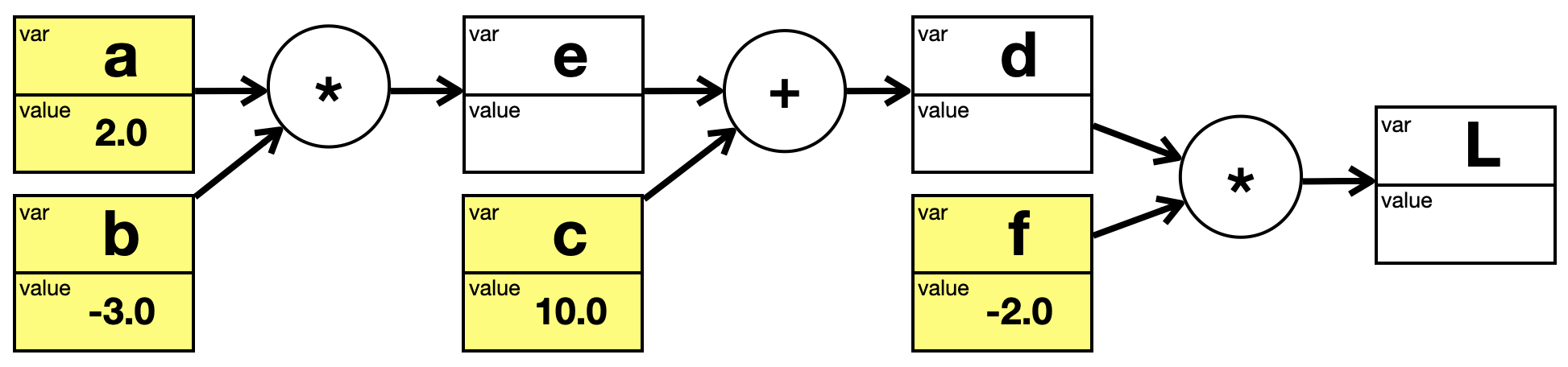
Jetzt ergänzen wir zwei weitere Formeln:
\[
\begin{align*}
e &= a \cdot b \\[2mm]
d &= e + c \\[2mm]
L &= d \cdot f
\end{align*}
\]
Die Berechnung von \(d\) hängt ab von \(e\) und die Berechnung von \(L\) hängt von \(d\) ab. Einige dieser Variablen (die Blätter) sollen wieder festgelegte Werte haben:
\[
\begin{align*}
a &:= 2 \\[2mm]
b &:= -3 \\[2mm]
c &:= 10 \\[2mm]
f &:= -2
\end{align*}
\]
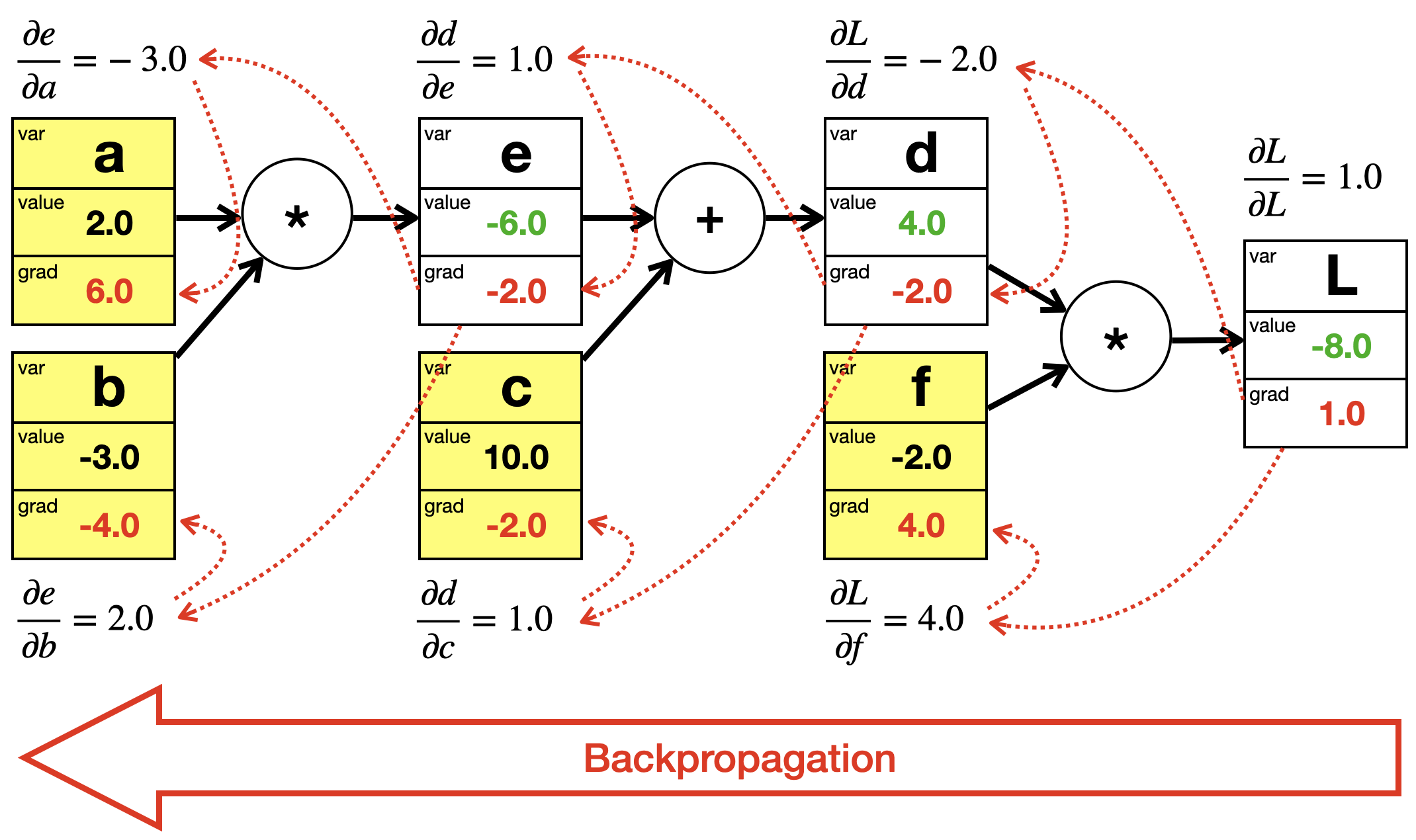
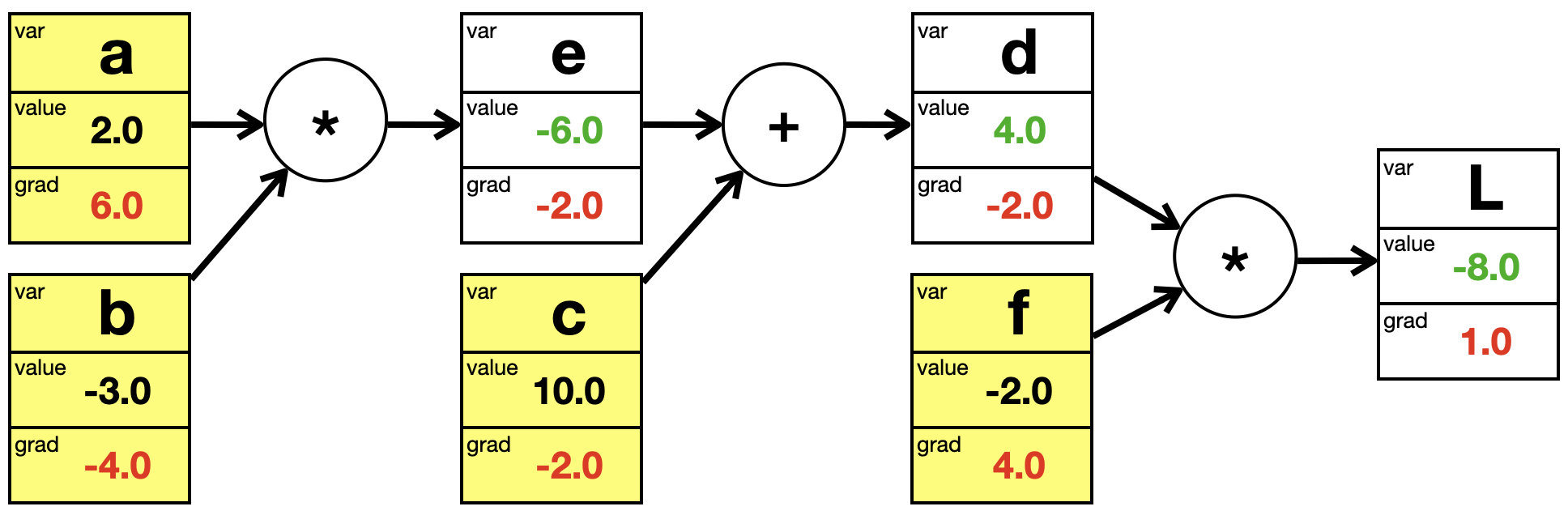
Wir können alles in einem einzigen Graphen darstellen, die Blätter sind wieder gelb markiert.
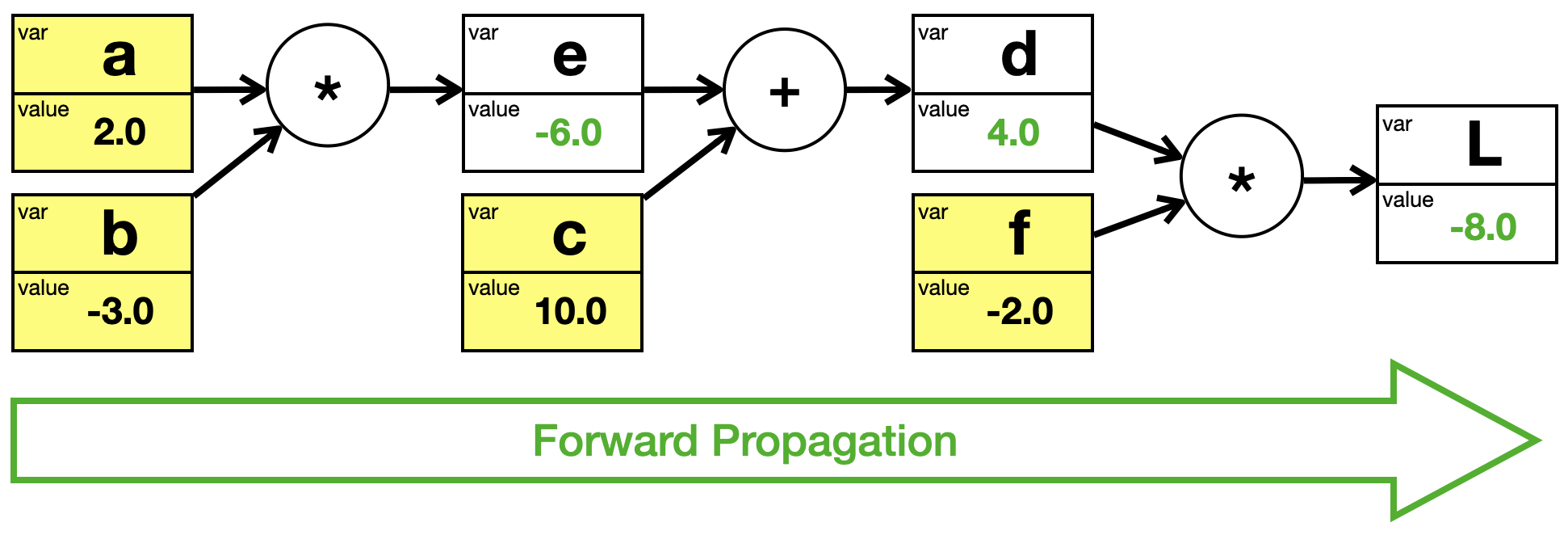
Wir führen einen Forward Pass von links nach rechts durch, um alle Werte zu berechnen. Die berechneten Werte sind wieder grün.
Man kann diesen Vorgang wie beim Neuronalen Netz auch Forward Propagation nennen.
7.2 Begriffklärung: Ableitungsformel vs. Gradientenwert
Bevor wir uns über Ableitungen und Gradienten unterhalten, sollten wir uns den Unterschied zwischen Ableitungsformel und Gradientenwert klarmachen.
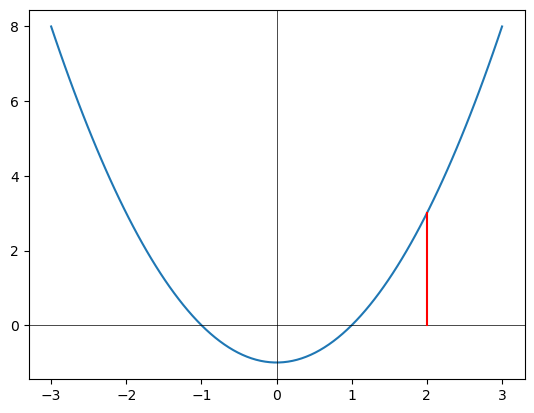
Betrachten wir eine einfache Funktion \(f\) mit einer Veränderlichen \(x\):
\[
f(x) = x^2 - 1
\]
Unten sehen Sie den Graphen von \(f\) mit Python gezeichnet.
Die Ableitungsformel beschreibt die symbolische Vorschrift zur Berechnung der Steigung von \(f(x)\) an jeder beliebigen Stelle \(x\):
\[
f'(x) = 2x
\]
Oder in der Leibniz-Schreibweise:
\[
\frac{df}{dx} (x) = 2x
\]
Die Ableitungsformel ist unabhängig davon, welchen genauen Wert \(x\) aktuell hat. Beachten Sie, wie mächtig so eine Formel ist. Egal, für welchen Wert \(x\) wir die Steigung benötigen, wir können diese mit einer einfachen Rechnung bestimmen.
Der Gradientenwert ist einfach die Steigung an einer konkreten Stelle \(x\), zum Beispiel für \(x = 2\) (siehe auch die Markierung in der Zeichnung unten):
\[
f'(2) = 2 \cdot 2 = 4
\]
Die Steigung von \(f\) an der Stelle \(x = 2\) ist \(4\). Es handelt sich also um einen Zahlenwert.
In der Mathematik und in der Literatur, ist der Begriff “Gradient” oft mehrdeutig. Meistens ist damit die Ableitungsformel gemeint, manchmal aber auch der konkrete Wert. Daher versuchen wir hier, die Begrifflichkeiten klar zu halten.
import numpy as npimport matplotlib.pyplot as pltx = np.linspace(-3, 3, 100)y = x**2-1plt.plot(x, y)plt.axhline(0, color='black', linewidth=0.5)plt.axvline(0, color='black', linewidth=0.5)plt.plot([2, 2], [0, 2**2-1], color='red') # Markierung bei x=2plt.show()
7.3 Berechnung der Gradientenwerte
Jetzt möchten wir sehen, wie der Einfluss einer Variablen wie \(a\) oder \(c\) auf unsere “Ausgangsvariable” \(L\) ist. Wenn wir Variable \(a\) ein wenig ändern, also von \(2\) zum Bespiel auf \(2.01\) oder auf \(1.99\), welche Auswirkung hätte das auf \(L\)?
Natürlich könnte man einfach \(a\) ändern und die Auswirkung quasi messen, aber das wäre umständlich, wenn man mehrere Milliarden von Parametern hat. Zum Glück wird dieser Zusammenhang eben genau von einer (partiellen) Ableitung beantwortet. Wie bekommen wir diese Ableitungen? Wir fangen zunächst “hinten” an mit unseren Überlegungen. Was ist der Wert der folgenden Ableitung?
\[
\frac{\partial L}{\partial L}
\]
Ganz einfach: Diese Ableitung hat den Wert 1. Denn wenn ich \(L\) um 1 erhöhe, erhöht sich \(L\) um 1. Das ist genau der Zusammengang, den eine Ableitung bemisst.
7.3.1 Gradient bei Multiplikation
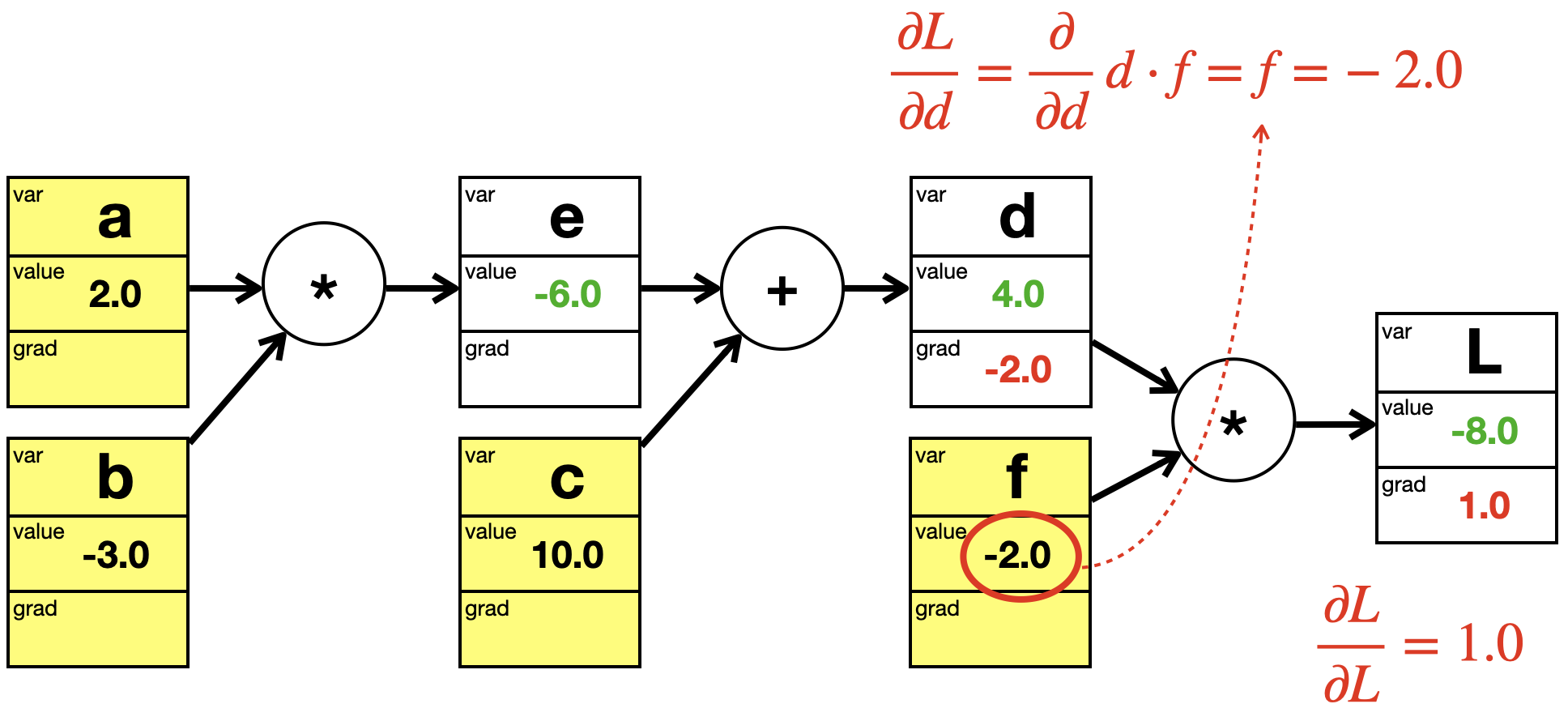
Welchen Wert hat jetzt die folgende Ableitung für die oben berechnete Situation?
\[
\frac{\partial L}{\partial d}
\]
Wir haben es hier mit einer Multiplikation zu tun:
\[
L = d \cdot f
\]
Hier leiten wir einfach ab.
\[
\frac{\partial L}{\partial d} = \frac{\partial }{\partial d} (d \cdot f ) = f
\]
Die partielle Ableitung ist eine Funktion mit Parameter \(f\):
\[
\frac{\partial L}{\partial d} (f) = f
\]
Jetzt setzen wir den Wert von \(f\) ein:
\[
\frac{\partial L}{\partial d} (-2.0) = -2.0
\]
In der Ableitungsformel und im Graphen sehen wir, dass wir für diese Ableitung den berechneten Wert des Geschwisterknotens benötigen.
Zu beachten ist folgender Unterschied:
die Ableitungsformel für die Berechnung des Gradienten \(\frac{\partial L}{\partial d} = f\); wie wir unten sehen, sprechen wir von der lokalen Ableitungsformel
der berechnete Gradientenwert bei der aktuellen Wertebelegung der Variablen
Sehen wir uns nochmal die lokalen Ableitungsformeln an, die ganz allgemein für die Operation einer einfachen Multiplikation gelten. Hier für die Knoten d und f im Graphen:
\[
\begin{align*}
L &= d \cdot f\\[2mm]
\frac{\partial L}{\partial d} &= f \\[2mm]
\frac{\partial L}{\partial f} &= d
\end{align*}
\]
Bildhaft gesprochen wird bei einer Multiplikation als Ableitungsformel immer der Wert des Geschwisterknoten genommen.
7.3.2 Gradient bei Addition und lokale Ableitungsformeln
In der Abbildung unten sehen Sie auch die Berechnung von
\[
\frac{\partial L}{\partial c}
\]
Zur Erinnerung:
\[
\begin{align*}
L &= d \cdot f \\[2mm]
e &= a \cdot b \\[2mm]
d &= e + c
\end{align*}
\]
Dieser Fall ist besonders interessant, weil hier zum ersten Mal die Kettenregel zum Zug kommt.
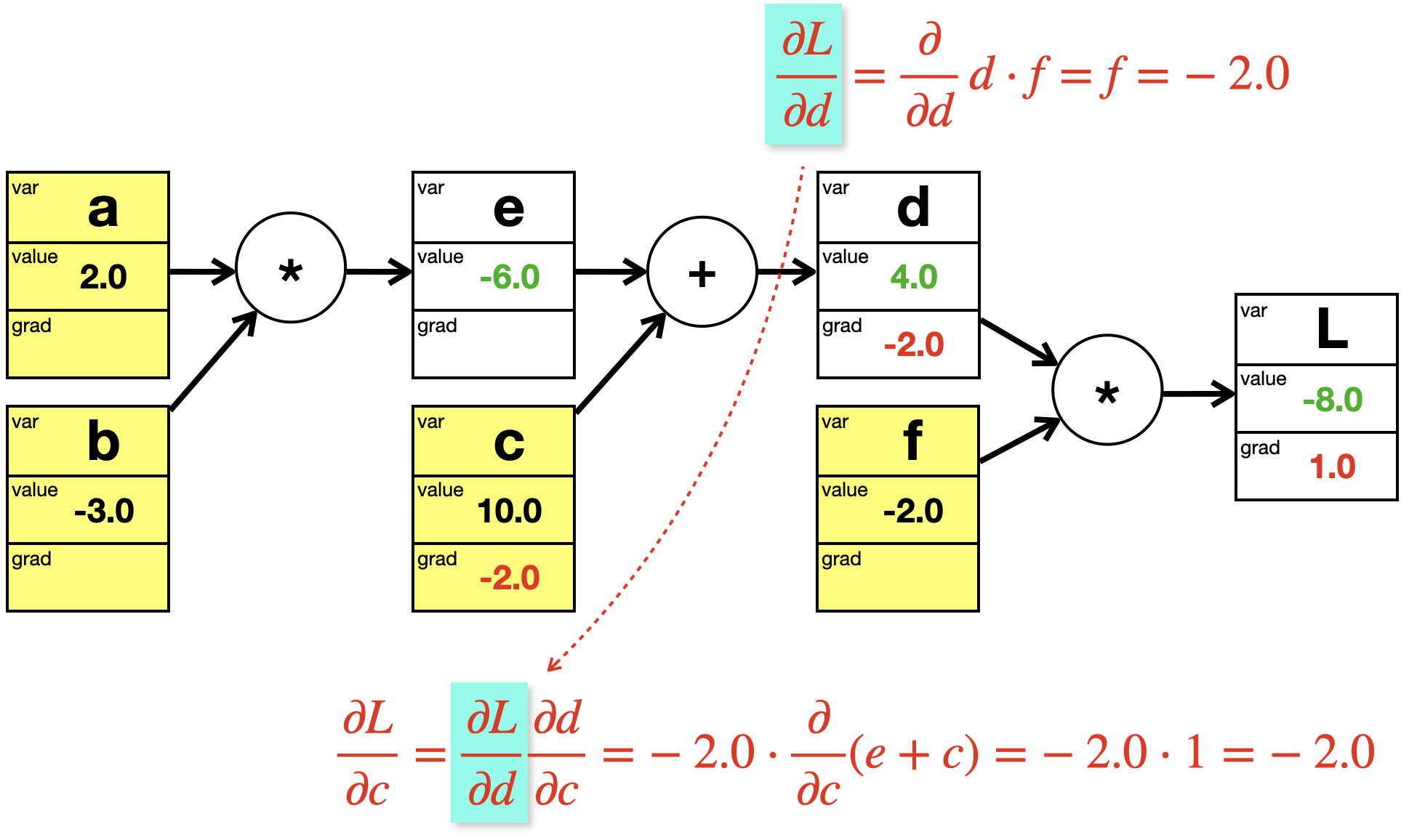
Wir konzentrieren uns zuerst auf die lokale Ableitungsformel\(\frac{\partial d}{\partial c}\). Diese Ableitung betrifft nur den Werte am direkten Ausgangsknoten \(d\). Da es sich mit \(d = e + c\) um eine einfach Addition handelt, ist die Ableitung auch denkbar einfach:
\[
\frac{\partial d}{\partial c} = 1
\]
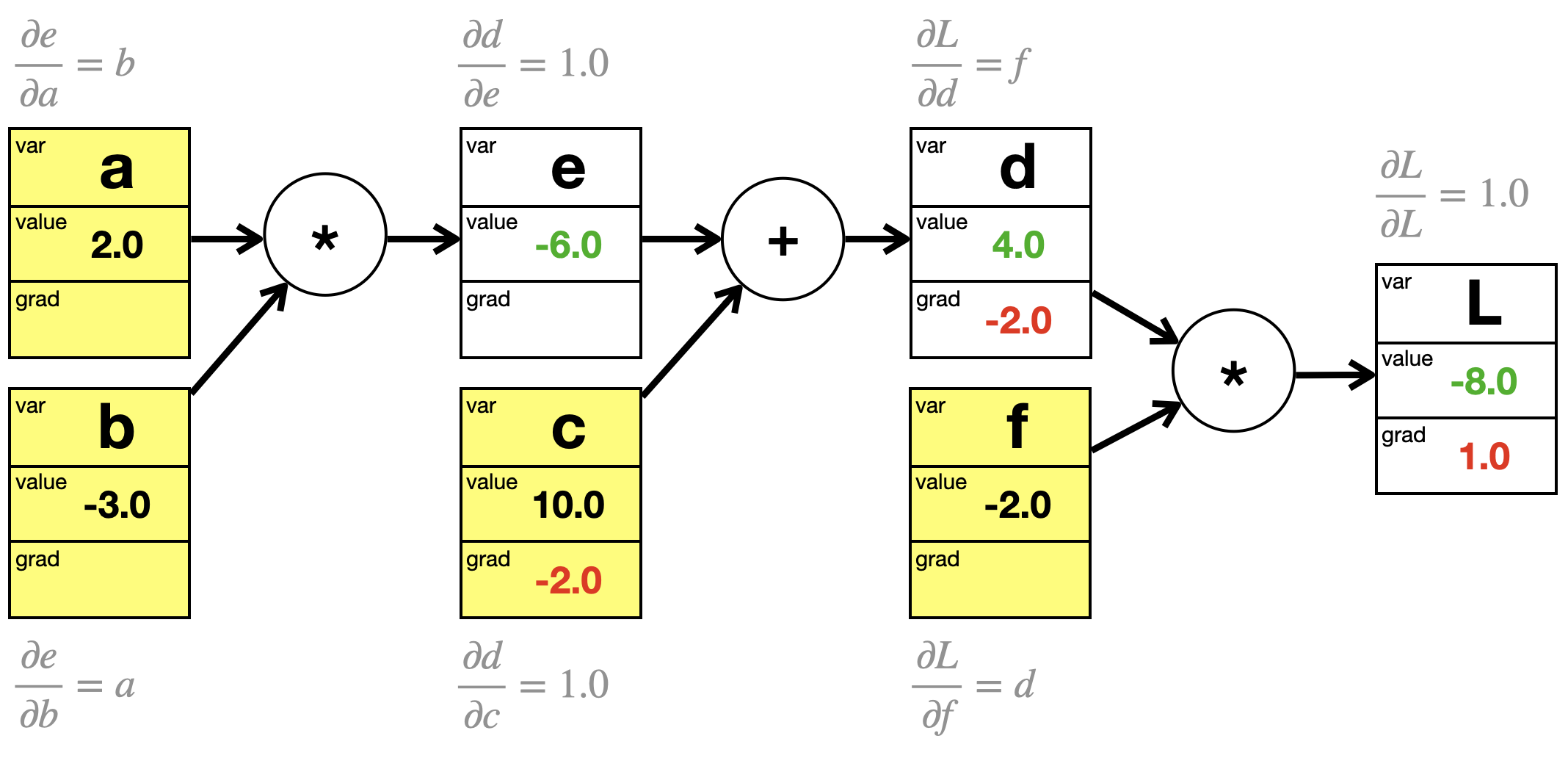
Wir haben jetzt die lokalen Ableitungsregeln für Addition und Multiplikation gesehen. Schauen wir uns das im Berechnungsgraphen an, wo wir für jeden Knoten die jeweils lokale Ableitungsformel hinzugefügt haben:
Da wir die Werte der Knoten bereits berechnet haben, können wir auch die lokalen Gradientenwerte für die lokalen Ableitungen berechnen:
Diese Werte sind aber nicht die Ableitungen bezüglich des letzten Knotens \(L\). Was noch fehlt ist die Anwendung der Kettenregel, um für jeden Knoten die Ableitung nach \(L\) zu berechnen. Dies machen wir mit Hilfe von Gradientenfluss.
7.3.3 Gradientenfluss
Wenn wir den Knoten c betrachten, ist die Ableitung nach \(L\) ist ja wie folgt:
Wir haben bislang die lokale Ableitung \(\frac{\partial d}{\partial c}\). Aber den Faktor \(\frac{\partial L}{\partial d}\) haben wir auch schon berechnet, als wir den Knoten d behandelt hatten.
Bei der Berechnung der Ableitung nach \(L\) benutzen wir also einfach das Ergebnis des nachfolgenden Knoten d. Man nennt das auch “Gradientenfluss”, da wir bei der Berechnung der Gradienten rückwärts durch den Graphen laufen. Die Kettenregel wird somit durch eine Reihe von Multiplikationen umgesetzt, wobei an jedem Knoten die jeweils “innere Ableitung” berechnet wird.
Auch hier unterscheiden wir wieder zwischen Ableitungsformel und aktuellem Gradientenwert, aber es kommt bei der Berechnung der Gradientenfluss hinzu:
die lokale Ableitungsformel für die Berechnung des lokalen Gradienten\(\frac{\partial d}{\partial c} = 1\); dies ist der Anteil des aktuellen Knotens am Gradienten
der Gradientenfluss für die Berechnung des Gradienten \(\frac{\partial L}{\partial e} = \frac{\partial L}{\partial d} \cdot \frac{\partial d}{\partial c} = 1 \cdot \frac{\partial d}{\partial c}\), die das \(\frac{\partial L}{\partial d}\) aus dem nachfolgenden Knoten nimmt; dies ist die Umsetzung der Kettenregel mit Hilfe des Berechnungsgraphen
der Berechnung des aktuellen Gradientenwerts bei der aktuellen Wertebelegung der Variablen, in diesem Fall \(-2.0\)
7.3.4 Gesamtbetrachtung
Reflektieren wir noch einmal, was genau passiert:
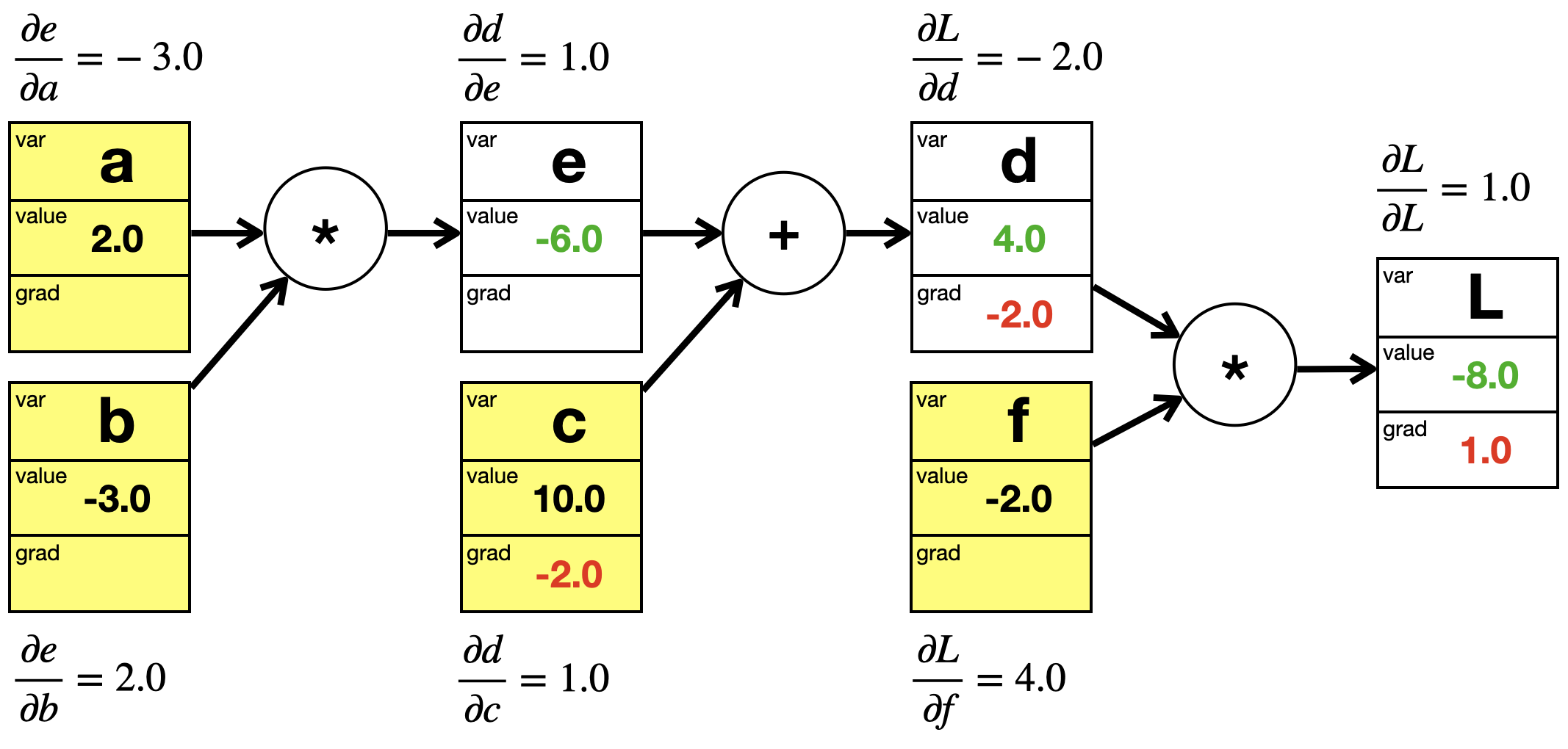
Bei der Forward Propagation werden die Werte der Variablen (rot) von links nach rechts berechnet.
An jedem Knoten gibt es eine lokale Ableitungsformel, die sich aus der jeweiligen Operation zum Knoten hin ergibt (Addition, Multiplikation).
Bei der Backward Propagation werden sowohl die lokalen Gradientenwerte berechnet als auch die finalen Gradientenwerte (rot), und zwar von rechts nach links. Während die lokalen Gradientenwert nur den Einfluss auf den nachfolgenden Knoten widerspiegeln, zeigt der finale Gradientenwert den Einfluss der jeweiligen Variable auf den letzten Knoten L. Das Aufmultiplizieren der lokalen Werte von hinten nach vorne nennt man Gradientenfluss und realisiert die Kettenregel, dargestellt durch die roten Pfeile.
Jetzt schauen wir uns an, wie diese Mechanismen in PyTorch und Keras benutzt werden können.
Variable mit mehreren Ausgängen
Was wir hier nicht betrachtet haben ist der Fall, dass eine Variable x mehrere “Ausgänge” y und z hat, was durchaus vorkommen kann, weil ein Wert mehrfach verwendet werden kann. In diesem Fall werden für x zwei unterschiedliche lokale Ableitungen/Gradienten für je y und z berechnet und auch zwei “finale” Ableitungen/Gradienten. Diese werden zum Schluss addiert. Man kann auch allgemeiner sagen, es werden im Backward-Pass für jeden “Pfad” separate Gradienten berechnet und anschließend werden alle Gradienten summiert.
7.4 Autograd in PyTorch
In PyTorch wird das automatische Differenzieren Autograd genannt für automatic gradient computation. Wir können unseren einfachen Berechnungsgraphen nachbilden und die Berechnung der Gradienten überprüfen.
Zunächst importieren wir PyTorch.
import torch
Wir legen zunächst die Blätter an (gelbe Knoten):
\[
\begin{align*}
a &:= 2 \\[2mm]
b &:= -3 \\[2mm]
c &:= 10 \\[2mm]
f &:= -2
\end{align*}
\]
Bei diesen Variablen müssen wir PyTorch mit requires_grad signalisieren, dass der jeweilige Gradient immer mitberechnet werden soll.
PyTorch kann nur für “Blätter” den Gradienten speichern. Der Grund ist, dass man bei Optimierungsproblemen nur die Gradienten von Blättern benötigt und PyTorch die Ressourcen schonen will. Parameter wie \(w_{i,j}\) oder \(b_i\) sind ja Blätter. Zwischenknoten wären z.B. die Rohinputs \(z\) oder die Aktivierungen \(a\) und die dortigen Gradienten sind nicht relevant (außer als Zwischenergebnis). Siehe auch die Discussion unter Why cant I see .grad of an intermediate variable?
Bei Keras gibt es diese Einschränkung nicht.
Jetzt berechnen wir die anderen Werte mit Hilfe der entsprechenden Formeln, die wir mit einfachen Variablenzuweisungen definieren:
\[
\begin{align*}
e &= a \cdot b \\[2mm]
d &= e + c \\[2mm]
L &= d \cdot f
\end{align*}
\]
PyTorch legt hier automatisch den Berechnungsgraphen an. Alle Variablen sind automatisch PyTorch-Tensoren. Hier findet natürlich direkt die Forward Propagation statt, denn die Werte der Variablen werden ausgerechnet.
e = a * bd = e + cL = d * fprint('e = ', e)print('d = ', d)print('L = ', L)
e = tensor(-6., grad_fn=<MulBackward0>)
d = tensor(4., grad_fn=<AddBackward0>)
L = tensor(-8., grad_fn=<MulBackward0>)
Mit der Funktion backward stoßen wir die Berechnung der Gradienten an. Wir geben uns diese auch direkt aus.
Auch in Keras bzw. TensorFlow gibt es Automatic Differentiation. Auch hier sehen wir uns das Beispiel von oben an.
Zunächst importieren wir TensorFlow.
import tensorflow as tf
Jetzt legen wir Variablen an. Dies sind unsere Blätter. Bei diesen Variablen legt TensorFlow bei Berechnungen im Hintergrund einen Graphen an.
a = tf.Variable(2.0)b = tf.Variable(-3.0)c = tf.Variable(10.0)f = tf.Variable(-2.0)
In TensorFlow benutzt man jetzt GradientTape als eine “Umgebung”, innerhalb derer Gradienten mitberechnet werden sollen. Wir können dann mit tape.gradient(L, a) die partielle Ableitung von \(L\) bezüglich \(a\) berechnen lassen.
with tf.GradientTape(persistent=True) as tape: e = a * b d = e + c L = d * fprint('a grad = ', tape.gradient(L, a))print('b grad = ', tape.gradient(L, b))print('c grad = ', tape.gradient(L, c))print('f grad = ', tape.gradient(L, f))print('\nd grad = ', tape.gradient(L, d))print('e grad = ', tape.gradient(L, e))print('L grad = ', tape.gradient(L, L))
a grad = tf.Tensor(6.0, shape=(), dtype=float32)
b grad = tf.Tensor(-4.0, shape=(), dtype=float32)
c grad = tf.Tensor(-2.0, shape=(), dtype=float32)
f grad = tf.Tensor(4.0, shape=(), dtype=float32)
d grad = tf.Tensor(-2.0, shape=(), dtype=float32)
e grad = tf.Tensor(-2.0, shape=(), dtype=float32)
L grad = tf.Tensor(1.0, shape=(), dtype=float32)
Hinweis zu “persistent”
Nach dem ersten Aufruf von gradient (hier tape.gradient(L, a)) kann man standardmäßig keine weiteren Gradienten abfragen. Daher haben wir hier persistent=True eingestellt, damit wir alle Gradienten auslesen können. Da tape persistent ist, kann man tape.gradient auch außerhalb des with aufrufen (das wird sogar ausdrücklich empfohlen).
Auch bei diesem TensorFlow-Beispiel können Sie kurz checken, ob die berechneten Werte stimmen (Gradienten in rot).
Sie sehen hier, dass auch an den Zwischenknoten \(d\), \(e\) und \(L\) die Gradienten ausgegeben werden können, auch wenn das in der Anwendung nicht notwendig ist (Gewichte sind alle Blätter).
7.6 Relevanz für Neuronale Netze und Backpropagation
Nachdem wir viele Beispiele für ein paar sehr simple Gleichungen gesehen haben, kommen wir nochmal auf die Neuronalen Netze zurück. Führen wir uns nochmal die Formeln für Forward Propagation vor Augen:
Sie sehen vielleicht, dass dies einem großen Berechnungsgraphen entspricht. Sie müssen sich diesen Graphen so vorstellen, dass “links” in der Eingabe aller Trainingsbeispiele eines Batch (also z.B. 32 Trainingsbeispiele) anliegen. Auf der Ausgabeseite, also “rechts”, haben wir eine große Summe in Form der Fehlerformel \(J\).
7.6.1 Einfaches Netz
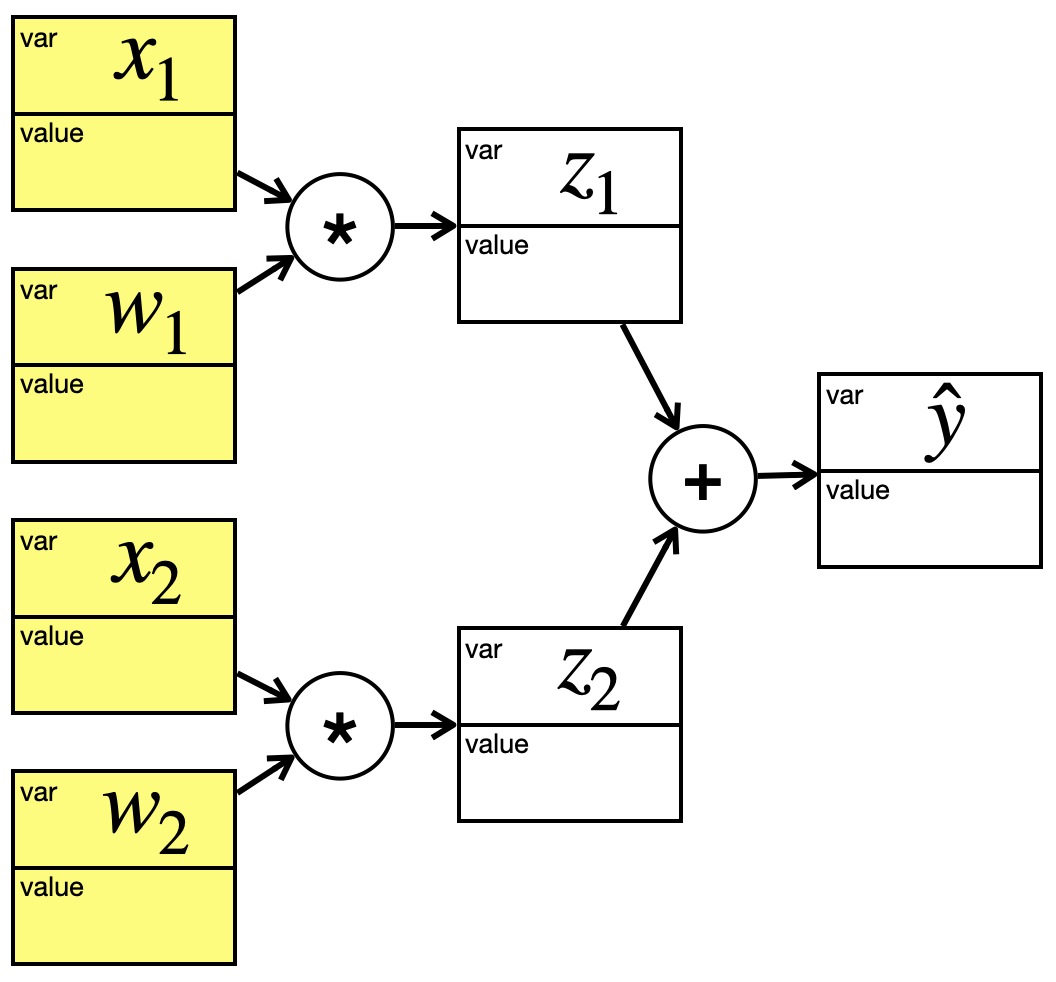
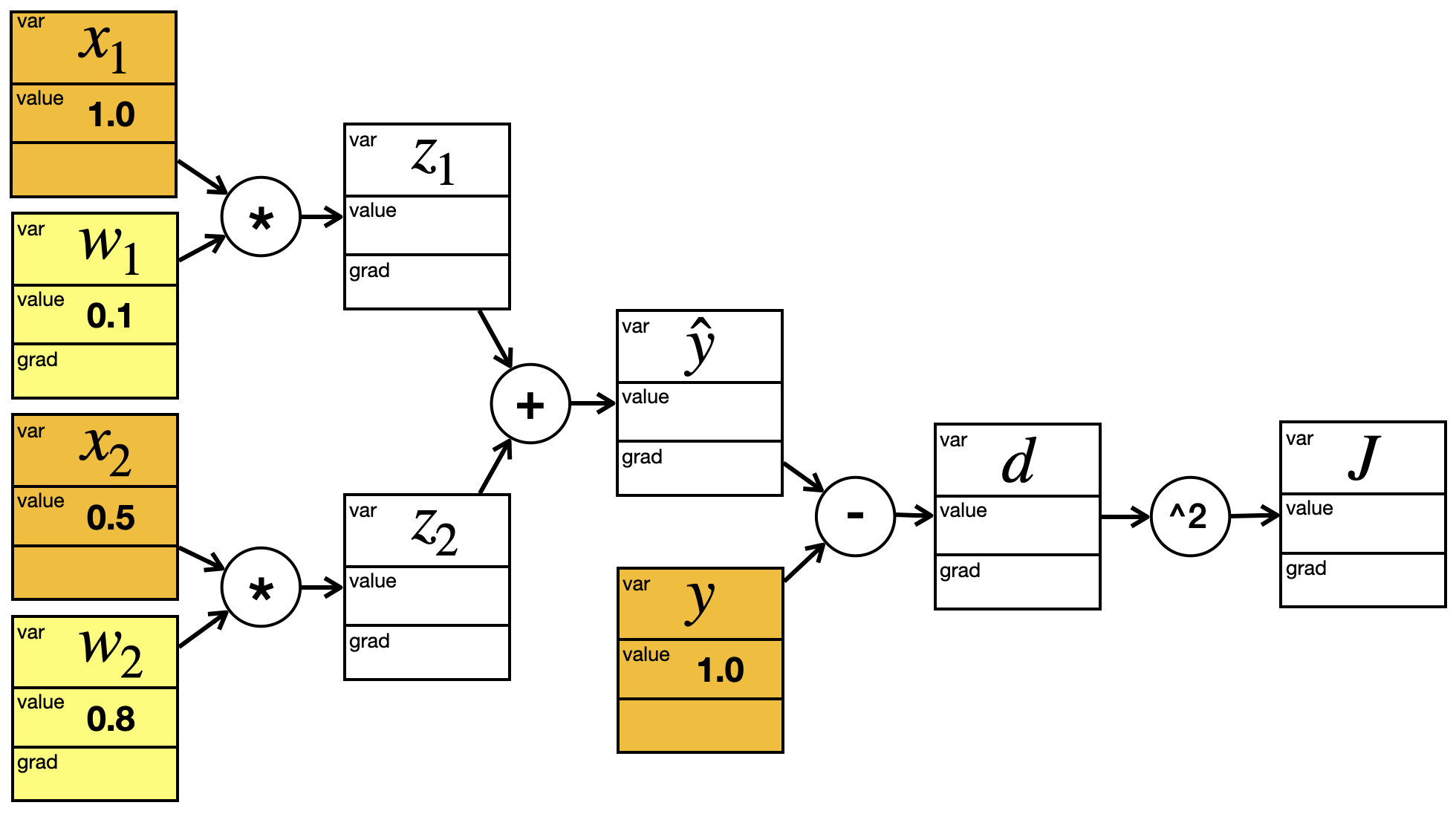
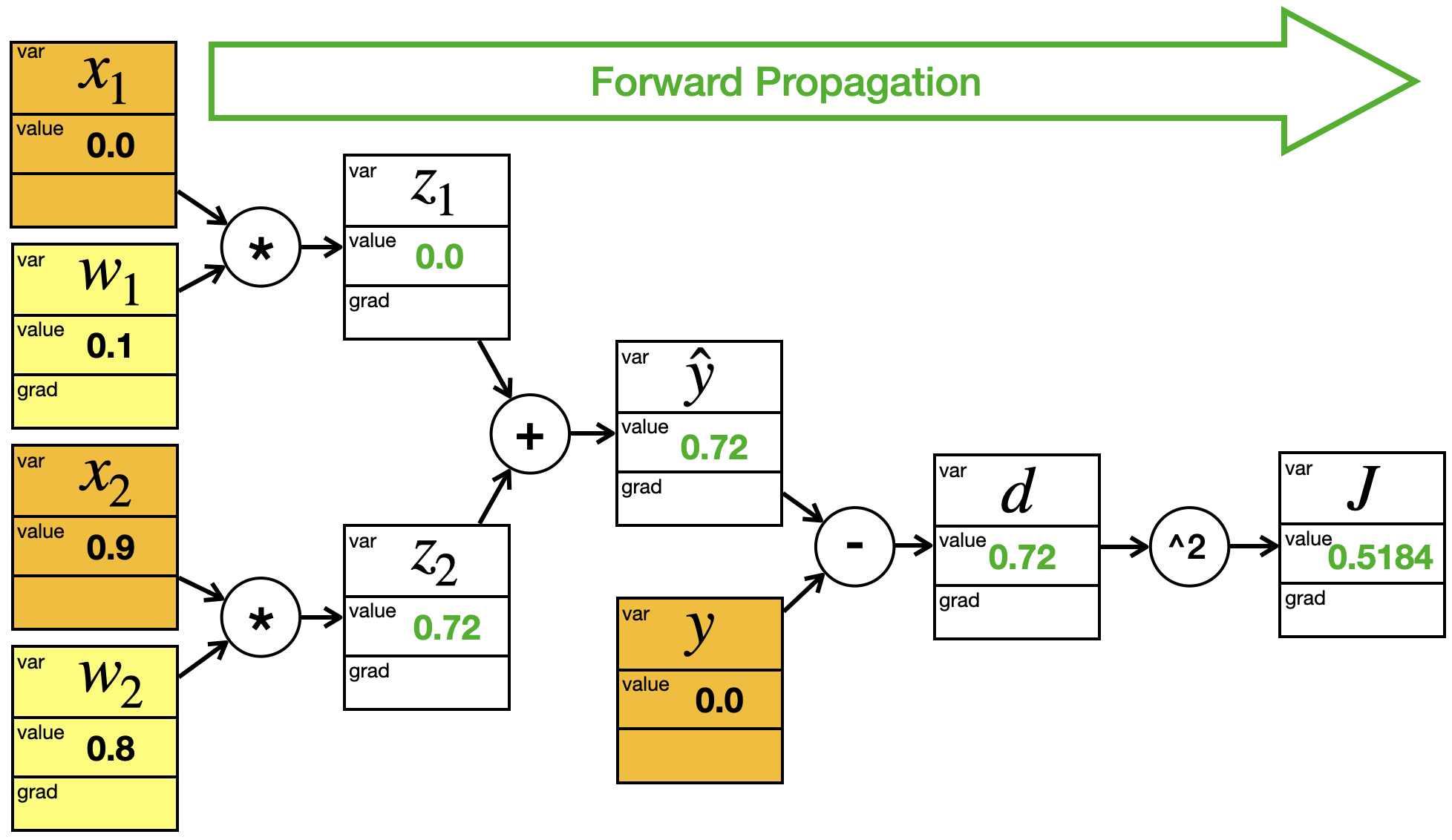
Wir sehen uns jetzt ein Beispiel an, das zwar auch stark vereinfacht ist, aber eher an ein Neuronales Netz erinnert. Wir nehmen uns zwei Eingabeneuronen \(x_1\) und \(x_2\), die über Gewichte direkt mit dem Output \(\hat{y}\) verbunden sind:
\[
\hat{y} = w_1 x_1 + w_2 x_2
\]
Wir würden das wie folgt in einen Graphen übertragen:
Wir haben Zwischenvariablen \(z_1\) und \(z_2\) eingefügt. Sie erinnern ein bisschen an den Rohinput.
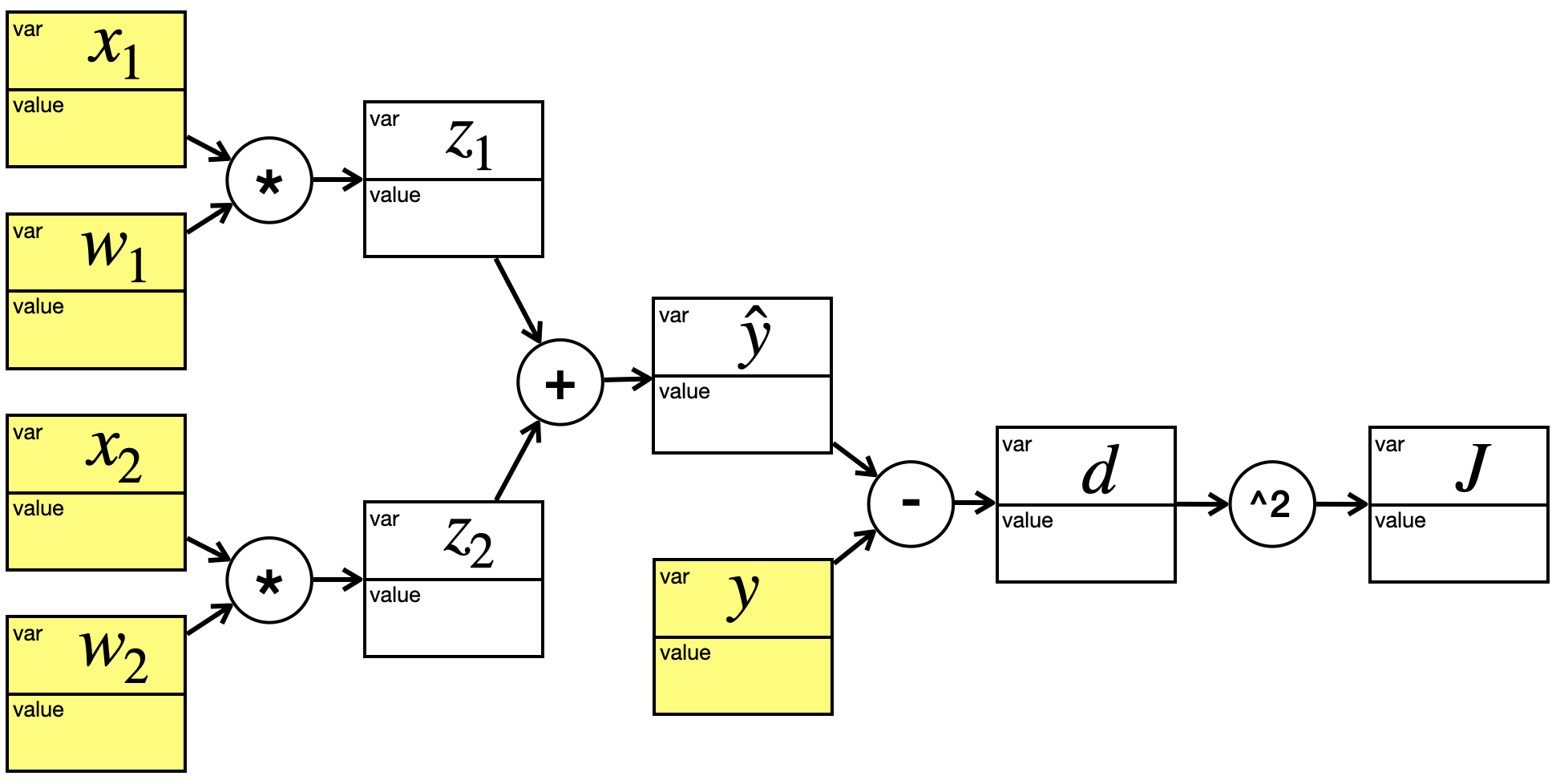
Jetzt wollen wir noch eine Art Fehlerfunktion einbauen:
\[
J = \left( \hat{y} - y \right)^2
\]
Diese Fehlerfunktion ist wirklich sehr einfach. Sie summiert nicht über alle Trainingsbeispiele, sondern misst nur den Fehler des aktuellen Beispiels. Für die Darstellung im Graphen spendieren wir noch eine Zwischenvariable \(d\) für die Differenz \(\hat{y} - y\):
Dieser Graph hat schon einige Ähnlichkeit mit dem, was in einem Neuronalen Netz passiert. Interessant ist hier die Unterscheidung zwischen “Blatt” (gelb) und “Zwischenknoten” (weiß). Die beiden Parameter \(w_1\) und \(w_2\), die wir ja am Ende des Tages anpassen wollen, sind beide Blätter. Die anderen Blätter – \(x_1\), \(x_2\) und \(y\) – kommen aus den Trainingsbeispielen.
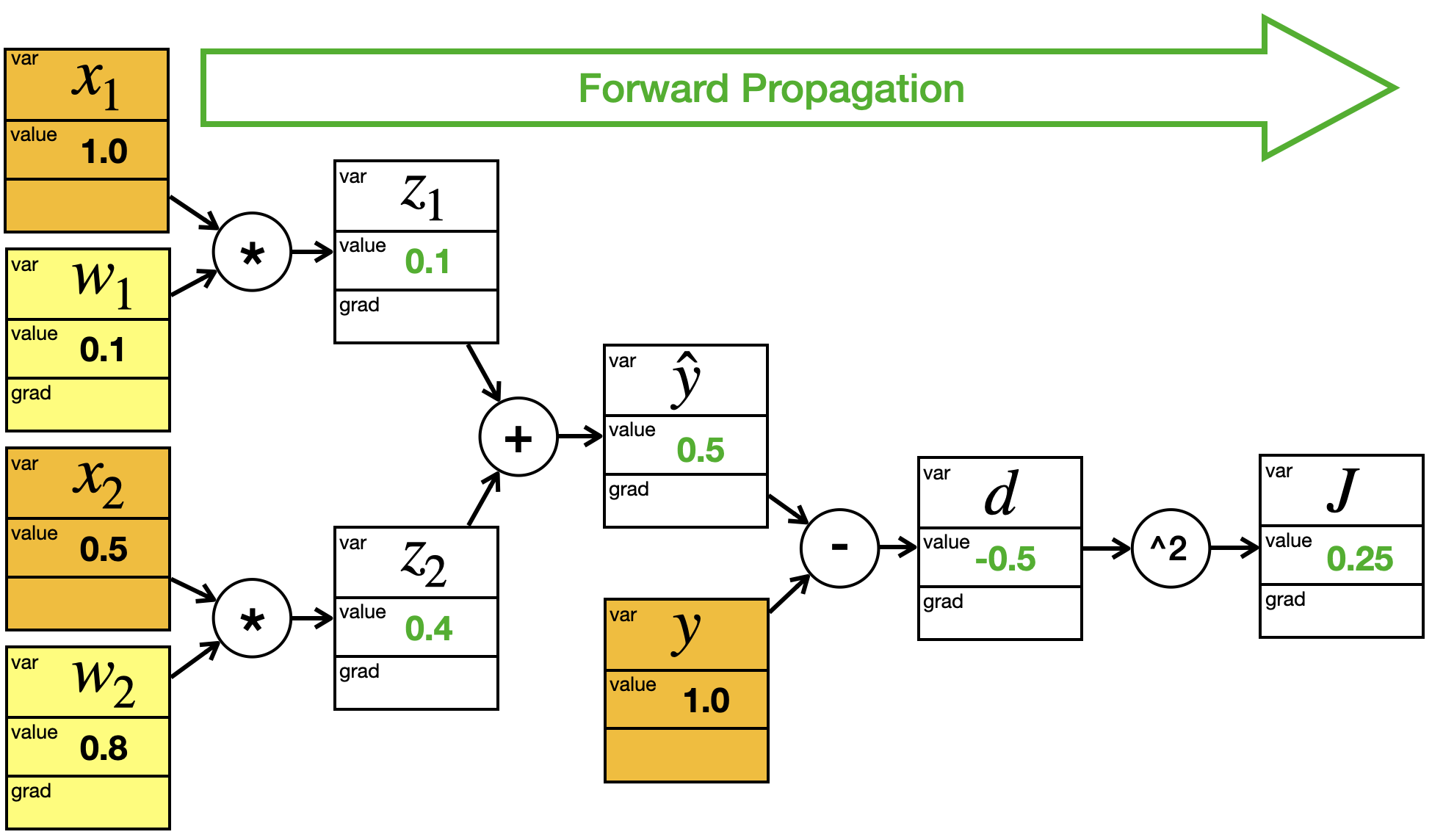
Jetzt sehen wir uns die Berechnung für zwei Trainingsbeispiele an. Die Gewichte sind dabei immer gleich. Wir setzen sie auf:
Wir übertragen die Werte für alle “Blätter” in unseren Graphen:
Im Graphen werden jetzt von links nach rechts die Werte an allen Zwischenknoten berechnet:
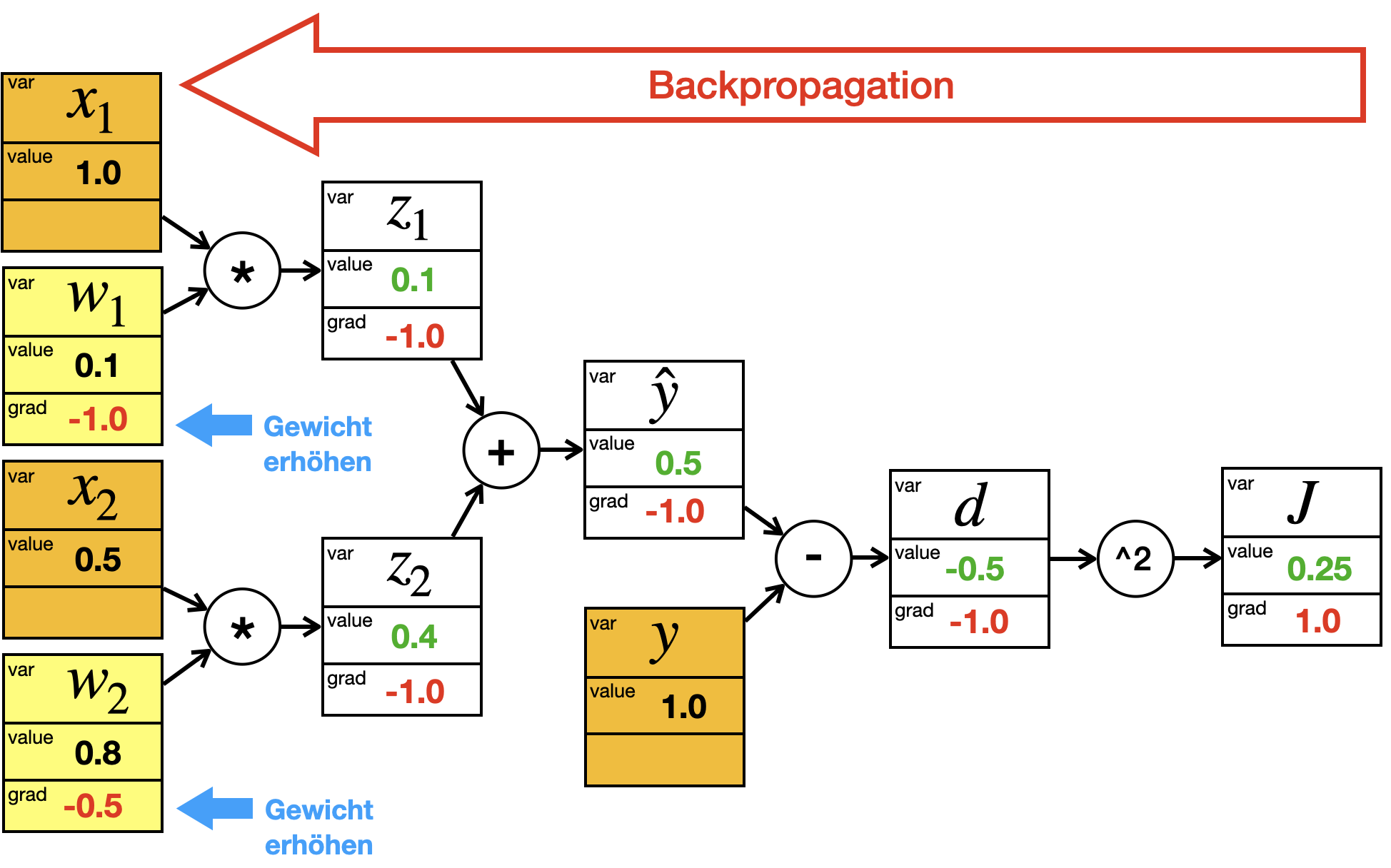
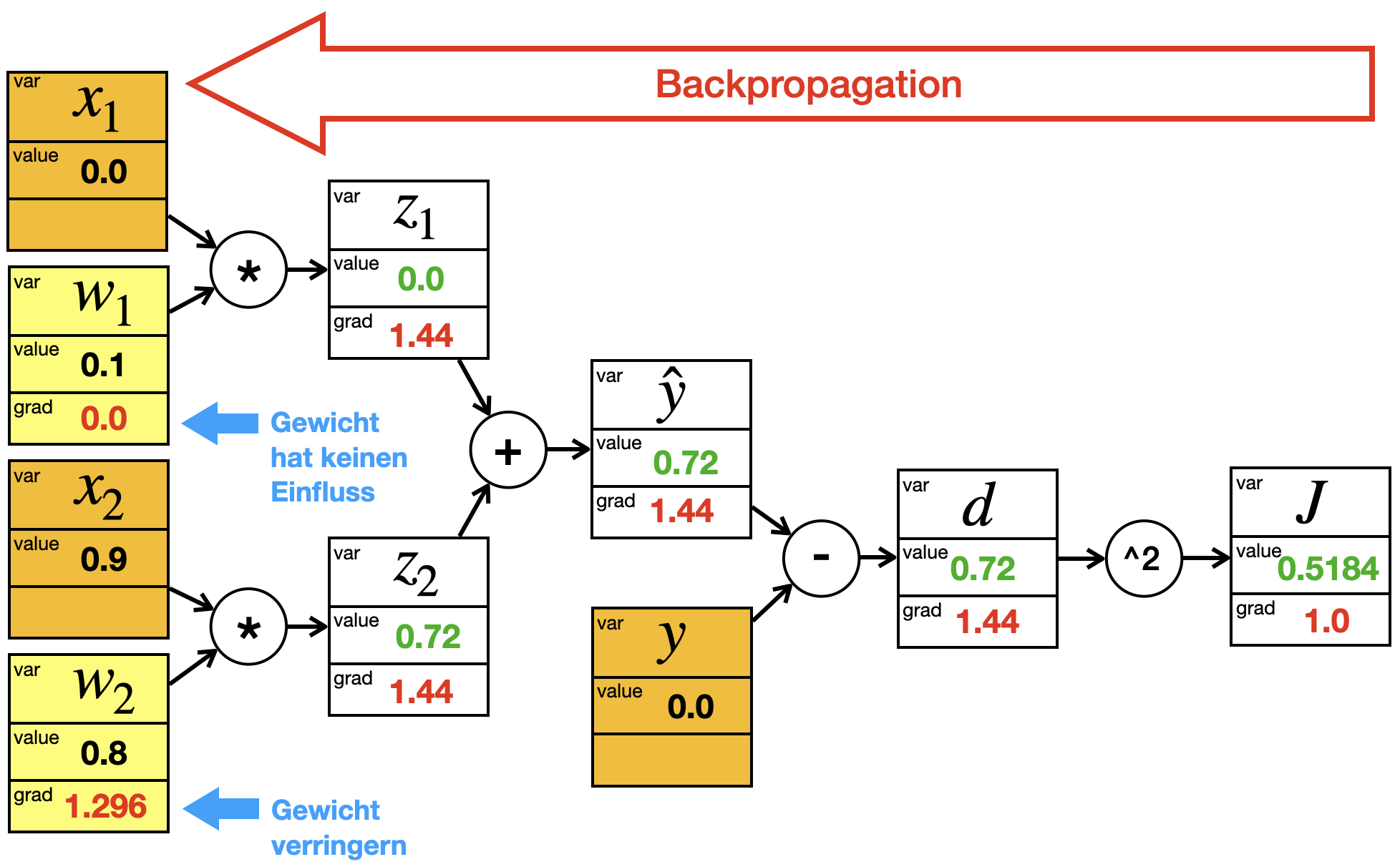
Anschließend werden über Backpropagation für alle Knoten die Gradienten berechnet. Sie sehen, dass für die Werte des Trainingsbeispiels, also \(x_1\), \(x_2\) und \(y\), die Gradienten uninteressant sind und deshalb hier weggellassen sind.
Sie sehen auch, dass die Gradienten bei \(w_1\) und \(w_2\) uns sagen, ob wir die Gewichte erhöhen oder verringern sollen. In beiden Fällen ist der Gradient negativ, d.h. wenn wir die Gewichte verringern erhöht sich der Fehler. Daher müssen wir die Gewichte erhöhen (umgekehrter Gradient).
7.6.3 Trainingsbeispiel 2
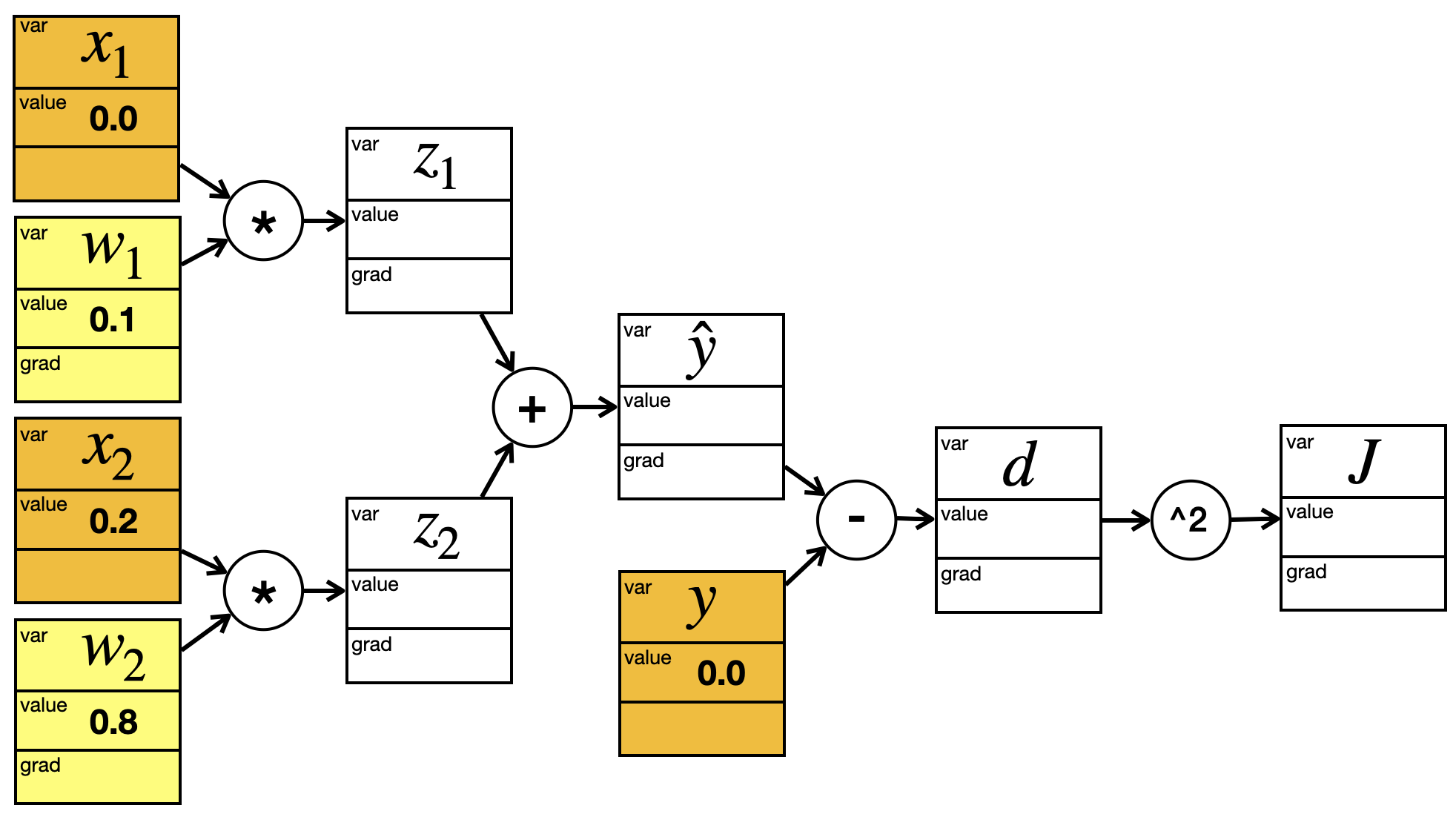
Wir behalten immer die alten Gewichte, aber ändern das Trainingsbeispiel, also das \(x\) und das \(y\):
Der Graph sieht jetzt wie folgt aus (die alten Gradienten wurden gelöscht):
Im Graphen werden die Werte mit Forward Propagation berechnet:
Anschließend werden die Gradienten mit Backpropagation ermittelt:
Bei \(w_1\) sehen wir, dass das Gewicht keinen Einfluss hat. Das ist klar, weil \(x_1 = 0\) und daher keine Aktivierung transportiert werden kann, egal, wie hoch oder niedrig \(w_1\) wäre. Bei \(w_2\) müssen wir das Gewicht verringern, da der Gradient positiv ist.
Wir hatten oben gesagt, dass die Gradienten beim zweiten Trainingsbeispiel gelöscht wurden. Es kann sinnvoll sein, dies nicht zu tun und stattdessen den neuen Gradienten zum alten zu addieren. Dies wird beim Batch-Training für alle Beispiele im Batch getan, um anschließend den Gradienten über die Batchgröße zu mitteln.
7.7 Fazit
Wie wir gesehen haben, haben Keras und PyTorch Mechanismen, wo die Gradienten an jedem Knoten automatisch berechnet werden. Diese Gradienten können wir direkt für Backpropagation einsetzen, da wir für Backpropagation im Grund “nur” für jedes Gewicht \(w\) die partielle Ableitung des Fehler bezüglich dieses Gewichts benötigen, also
\[
\frac{\partial J}{\partial w}
\]
Genau dies bekommen wir aber durch Automatic Differentiation. Die automatische Berechnung von Gradienten in Berechnungsgraphen ist die Verallgemeinerung unseres Backpropagation-Verfahrens und daher für jegliche Art der Parameteranpassung geeignet.